The dozens of studies on academic discourse carried out over the past 20 years have mostly focused on written academic prose (usually the technical research article in science or medicine) or on academic lectures. Other registers that may be more important for students adjusting to university life, such as textbooks, have received surprisingly little attention, and spoken registers such as study groups or on-campus service encounters have been virtually ignored. To explain more fully the nature of the tasks that incoming international students encounter, this article undertakes a comprehensive linguistic description of the range of spoken and written registers at U.S. universities. Specifically, the article describes a multidimensional analysis of register variation in the TOEFL 2000 Spoken and Written Academic Language Corpus. The analysis shows that spoken registers are fundamentally different from written ones in university contexts, regardless of purpose. Some of the register characterizations are particularly surprising. For example, classroom teaching was similar to the conversational registers in many respects, and departmental brochures and Web pages were as informationally dense as textbooks. The article discusses the implications of these findings for pedagogy and future research.
Teachers, textbook authors, and test developers are constantly faced with decisions regarding the language forms, topics, and functions to include in ESOL materials. Unfortunately, few empirical linguistic descriptions are available to inform these decisions. As a result, language professionals rely on intuitions and anecdotal evidence of how speakers and writers use language. Despite the value of intuitions in materials development, intuitions about language use often turn out to be wrong (see Biber & Conrad, 2001; Biber & Reppen, in press). Comprehensive linguistic descriptions are not all that materials developers need, but such descriptions provide essential information for making principled pedagogical decisions. The research reported in this article contributes empirically based linguistic description intended to inform materials development for university-level English language instruction.
TESOL professionals are aware of the special demands of academic reading and writing, especially in relation to textbooks, research papers, and student essays and term papers. Teachers also recognize the importance of academic listening skills, which are required for success in the classroom. However, considerably less attention has been directed toward other university registers, such as study groups, office hours, and course packs. Institutional registers that may be particularly important for students to negotiate include written registers—such as handbooks, catalogues, program Web pages, and course syllabi—and spoken registers, such as service encounters with the registrar or departmental staff and the classroom management talk of instructors at the beginning of class sessions. Little is known about the linguistic characteristics of these registers, so it is not surprising that most programs and textbooks do not address the language skills required to handle them.
To better understand the nature of the language that incoming international (and domestic) students encounter in the university, and ultimately to help students develop the language skills required, TESOL professionals need a comprehensive linguistic description of all spoken and written registers used at the university. This article reports results of the most comprehensive linguistic analysis of academic language to date. The study draws on quantitative linguistic analysis of the TOEFL 2000 Spoken and Written Academic Language (T2K-SWAL) Corpus, which was designed to represent the full range of spoken and written registers used at U.S. universities (e.g., classroom teaching, office hours, study groups, textbooks) as well as in the major academic disciplines (e.g., humanities, natural sciences) and academic levels (lower division, upper division, and graduate).
The many studies on academic discourse published over the past 20 years have been undertaken from a variety of perspectives (see, e.g., the extensive survey of research in Grabe & Kaplan, 1996). Many of these studies adopt a rhetorical or social/historical perspective, describing the rhetorical structure of academic texts and the way the practices of researchers in particular discourse communities shape the conventions of academic genres. Most studies focus on written scientific or medical prose (see, e.g., the book-length studies by Atkinson, 1999; Bazerman, 1988; Berkenkotter & Huckin, 1995; Gilbert & Mulkay, 1984; Halliday & Martin, 1993; Swales, 1990; Valle, 1999).
Other studies describe the surface linguistic characteristics of academic texts, again focusing mostly on written academic registers, espe- cially academic research articles in science or medicine. The hedging devices used in academic texts have been particularly well researched (see, e.g., Crompton, 1997; Grabe & Kaplan, 1997; Holmes, 1988; Hyland, 1994, 1996a, 1996b). Several other studies document the special classes of verbs used in research articles (e.g., Hunston, 1995; Thompson & Ye, 1991; Williams, 1996) and the complex noun phrase structures typical of scientific prose (e.g., Halliday, 1988; Love, 1993; Varantola, 1984). Other analysts have described specialized linguistic features, such as imperatives (Swales et al., 1998), conditionals (Ferguson, 2000), personal pronouns (Kuo, 1999), existential there (Huckin & Pesante, 1988), politeness markers (Myers, 1989), citation patterns (Salager-Meyer, 1999), procedural vocabulary (Marco, 1999), and collocational frames (Marco, 2000). At the other extreme, as part of a corpus-based reference grammar, Biber, Johansson, Leech, Conrad, and Finegan (1999) describe the grammatical features in academic prose in compari- son with those in conversation, ction, and newspaper reportage. Atkinson (1992, 1996, 1999) and Conrad (1996, 2001) describe the characteristics of professional written registers with respect to a large number of co-occurring linguistic features (see the section Multidimen- sional Analysis below).
Few studies have described the linguistic characteristics of spoken academic discourse. The numerous studies of the rhetorical organization of classroom discourse (see, e.g., Cazden, 1988) have focused for the most part on discourse markers and other relatively fixed lexical chunks (e.g., Chaudron & Richards, 1986; Flowerdew & Tauroza, 1995; Khuwaileh, 1999; Nattinger & DeCarrico, 1992; Strodt-Lopez, 1991) or on the overall discourse organization of the lecture (see, e.g., the papers in Flowerdew, 1994). Carson, Chase, Gibson, and Hargrove (1992) discuss how undergraduates are required to integrate written and spoken registers, specifically by reading textbooks to prepare to listen to lectures. Even fewer studies have described the linguistic characteristics of other spoken registers common in university life. A recent exception to this generalization is Cutting’s (1999) analysis of the conversations of a group of postgraduate students.
This review of past studies in academic discourse reveals a focus on written academic prose and academic lectures, with the overwhelming majority of the research on the technical research article (in science or medicine). Past work has neglected other registers important for students, such as textbooks and spoken registers (e.g., study groups or on-campus service encounters).
To help international university students develop the language skills they need, TESOL professionals might benefit from a comprehensive linguistic description of all university spoken and written registers, including textbooks and classroom teaching experiences. Equally important, although perhaps less obvious, are the “gatekeeping” registers, like university catalogues, departmental Web pages, course syllabi, class management talk (in which instructors describe course requirements and expectations), and service encounters (in which newly arrived students interact with office staff to accomplish the business of becoming a student). In sum, the TESOL profession needs fuller linguistic descriptions as the basis for ESL and English for academic purposes (EAP) materials that represent the full extent of ESL students’ future university tasks.
Question
What types of linguistic characteristics have been studied in academic discourse?
Answer the question above the continue reading. iTELL evaluation is based on AI and may not always be accurate.
Previous research on academic discourse has been limited in part simply because researchers have been interested in specific registers or linguistic features rather than the overall patterns of register variation. In addition, more comprehensive investigations have not been feasible until recently. The combined use of computer programs for automated language processing and representative text corpora enables such comprehensive investigations (cf. Biber, Conrad, & Reppen, 1998). Corpus-based analysis allows for the following essentials:
Taking advantage of these potentials for linguistic analysis, our study of academic registers used a quantitative, corpus-based technique called multidimensional (MD) analysis. MD analysis was developed to discover and interpret the patterns of linguistic variation found in a corpus of texts. Early researchers in sociolinguistics (e.g., Ervin-Tripp, 1972) argued that linguistic features work together in texts as constellations of co-occurring features (rather than as individual features) to distinguish among registers. Although this theoretical perspective is widely accepted, before the availability of corpus-based techniques, linguists lacked the methodological tools required to analyze these co-occurring features. MD analysis uses multivariate statistical techniques to investigate the quantitative distribution of linguistic features across texts and text varieties and to analyze linguistic co-occurrence by identifying underlying dimensions of variation through a statistical factor analysis.
The dimensions identified in MD analysis have both linguistic and functional interpretations. The linguistic content is a group of features (e.g., nouns, attributive adjectives, prepositional phrases) that co-occur with a markedly high frequency in texts. On the assumption that co-occurrence markedly reflects shared functions, analysts interpret the co-occurrence patterns to assess the situational, social, and cognitive functions most widely shared by the linguistic features. For example, the frequent co-occurrence of first-person pronouns, second-person pronouns, hedges, and emphatics in conversational texts is interpreted as reflecting directly interactive situations and a primary focus on personal stance and involvement (see below).
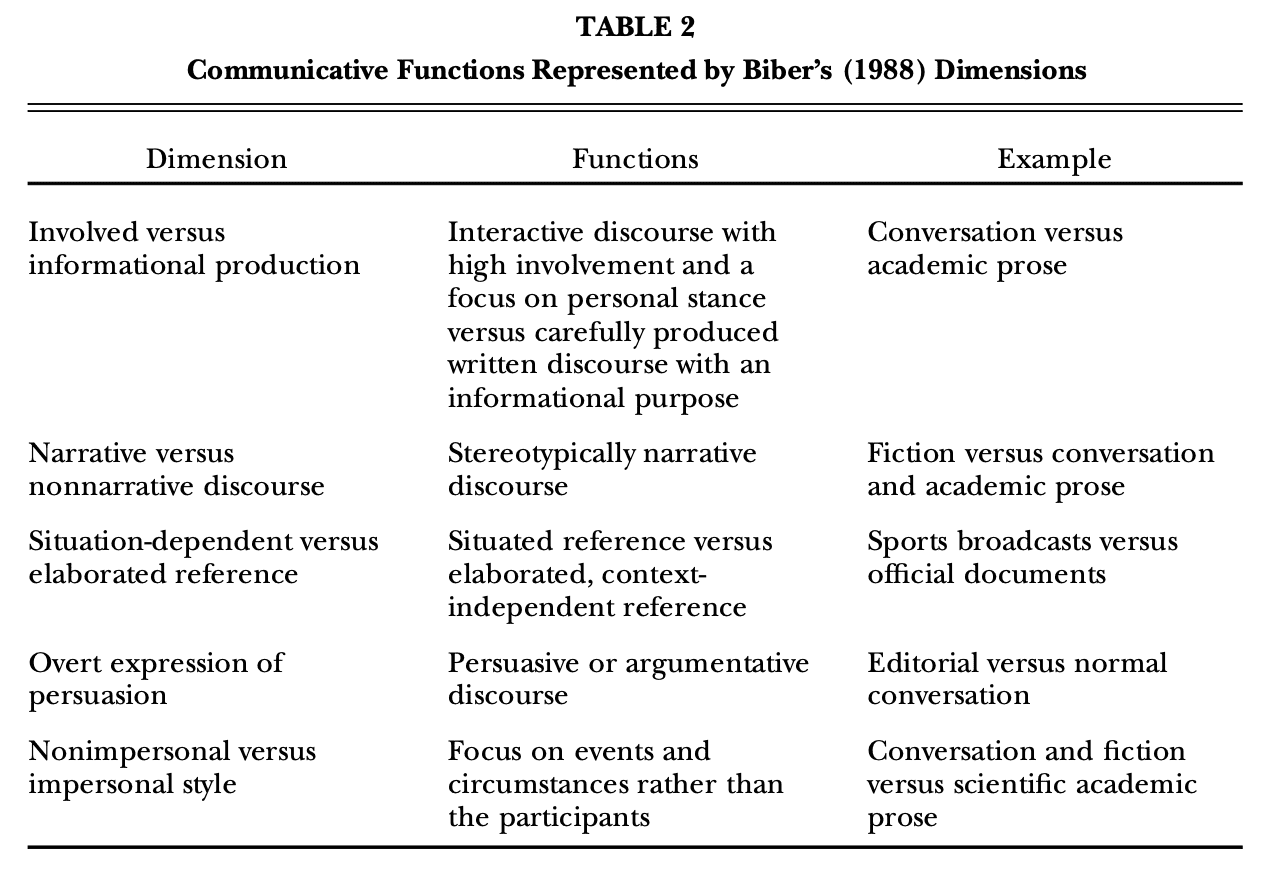
Biber (1988) identified five main dimensions of variation in a general corpus of spoken and written registers. He used factor analysis to identify the groups of linguistic features associated with each dimension (i.e., the linguistic features that co-occur in texts with markedly high frequencies; see Table 1).


The dimensions represent the co-occurrence distributions of 67 linguistic features across 481 spoken and written texts of contemporary British English. The texts, taken from the Lancaster-Oslo-Bergen Corpus and the London-Lund Corpus, represent 23 major register categories (e.g., academic prose, press reportage, fiction, letters, conversations, interviews, radio broadcasts, public speeches). The factor loadings for a linguistic feature (Table 1, third column) can range from 21.0 to +1.0; the farther from 0.0 a loading is, the stronger the association between the feature and the dimension. Features with higher loadings are thus better representatives of the dimension underlying a factor.
Most of the dimensions consist of two groupings of features, one with positive and the other with negative loadings. The positive and negative sets represent features that occur in a complementary pattern. That is, when the features in one group occur together frequently in a text, the features in the other group are markedly less frequent in that text, and vice versa.
Interpretations of the dimensions should consider likely reasons for the complementary distribution of these two groups of features as well as the reasons for the co-occurrence pattern within each group. For example, on Dimension 1, the interpretation of the features having negative loadings is relatively straightforward because the features are relatively few in number. Nouns, word length, prepositions, type/token ratio, and attributive adjectives all have negative loadings larger than .45, and no feature has a larger loading on another factor. High frequencies of all these features indicate an informational focus and a careful integration of information in a text. These features are associated with texts that have an informational purpose and provide ample opportunity for careful integration of information and precise lexical choice.
The set of features with positive loadings on Dimension 1 is more complex, although all of these features have been associated with an involved, noninformational focus related to a primarily interactive or affective purpose and on-line production circumstances. For example, first- and second-person pronouns, wh- questions, emphatics, amplifiers, and sentence relatives can all be interpreted as reflecting interpersonal interaction and the involved expression of personal feelings and concerns. Other features with positive loadings on Dimension 1 mark a reduced surface form, a generalized or uncertain presentation of information, and a generally fragmented production of text; these include that-deletions, contractions, pro-verb do, the pronominal forms, and final (stranded) prepositions. In these cases, a reduction in surface form also results in a more generalized, less explicit content.
Overall, based on both positive and negative co-occurring linguistic features, Dimension 1 seems to represent a dimension marking affective, interactional, and generalized content (the features with positive loadings) versus high informational density and precise informational content (the features with negative loadings). Two separate communicative parameters seem to be represented here: the primary purpose of the writer/speaker (involved vs. informational) and the production circumstances (those dictated by real-time constraints vs. those enabling careful editing possibilities). Reflecting both of these parameters, the interpretive label involved versus informational production seems appropriate for this dimension.
The complementary groupings of features on the other factors shown in Table 1 redirect other functional relations. The interpretive labels for the dimensions (involved versus informational production, narrative versus nonnarrative discourse, situation-dependent versus elaborated reference, overt expression of persuasion, and nonimpersonal versus impersonal style) express the communicative function(s) they represent (see Table 2). Biber (1988, chapters 6–7; 1995, chapters 5–7) and Conrad and Biber (2001, chapter 2) provide justification for these interpretations based on the shared communicative functions of the co-occurring linguistic features on each dimension plus the distribution of registers along each dimension.
Having defined these dimensions empirically through quantities of linguistic characteristics, we can analyze any text by computing its dimension score: a summation of the frequencies for those features having salient loadings on a dimension. Registers and subregisters can then be compared in terms of their mean dimension scores. Considering all five dimensions together enables multidimensional analyses of the linguistic characteristics of particular registers and the linguistic differences among registers.
Biber (1988) used these dimensions to compare and contrast a wide variety of spoken and written registers (including conversation, personal letters, fiction, and academic prose). Subsequent studies have used the dimensions to analyze academic registers in greater detail. For example, Conrad (1996, 2001) compared the multidimensional characteristics of research articles and textbooks in the academic disciplines of ecology and American history. This study provides a baseline for the study of writing development, comparing the characteristics of term papers written by students at various levels to the characteristics of professional written texts. Carkin (2001) focused on introductory textbooks and lectures, using the dimensions for a four-way comparison of lower-division textbooks and lectures in economics and biology. Biber and Finegan (1994) compared the multidimensional profiles of the introduction-methods-results-discussion sections in medical research articles. Csomay (2000) used a modified MD analysis to investigate the characteristics of academic lectures. Other studies have used the five dimensions to track historical patterns of change within academic written registers, focusing especially on medical prose and science prose (Atkinson, 1992, 1996, 1999; Biber, 1995, chapter 8; Biber & Finegan, 1997; see also the papers in Conrad & Biber, 2001). Taken together, these studies demonstrate the power of the Biber’s (1988) multidimensional framework for building descriptions of academic registers.
While continuing to investigate academic discourse, the present study takes a broader perspective than these previous investigations did. Rather than focus on a few stereotypically academic registers, we analyze a full range of registers encountered by students in university life. Some of these registers—such as classroom teaching, office hours, and study groups—are influenced by competing functional forces, for example, the need to convey information efficiently versus the restrictions of real-time (spoken) production and the need for social interaction. But how are these and other, competing functional influences reflected in the language of the texts in each register? To investigate this question, we locate each academic register along the five register dimensions described above.
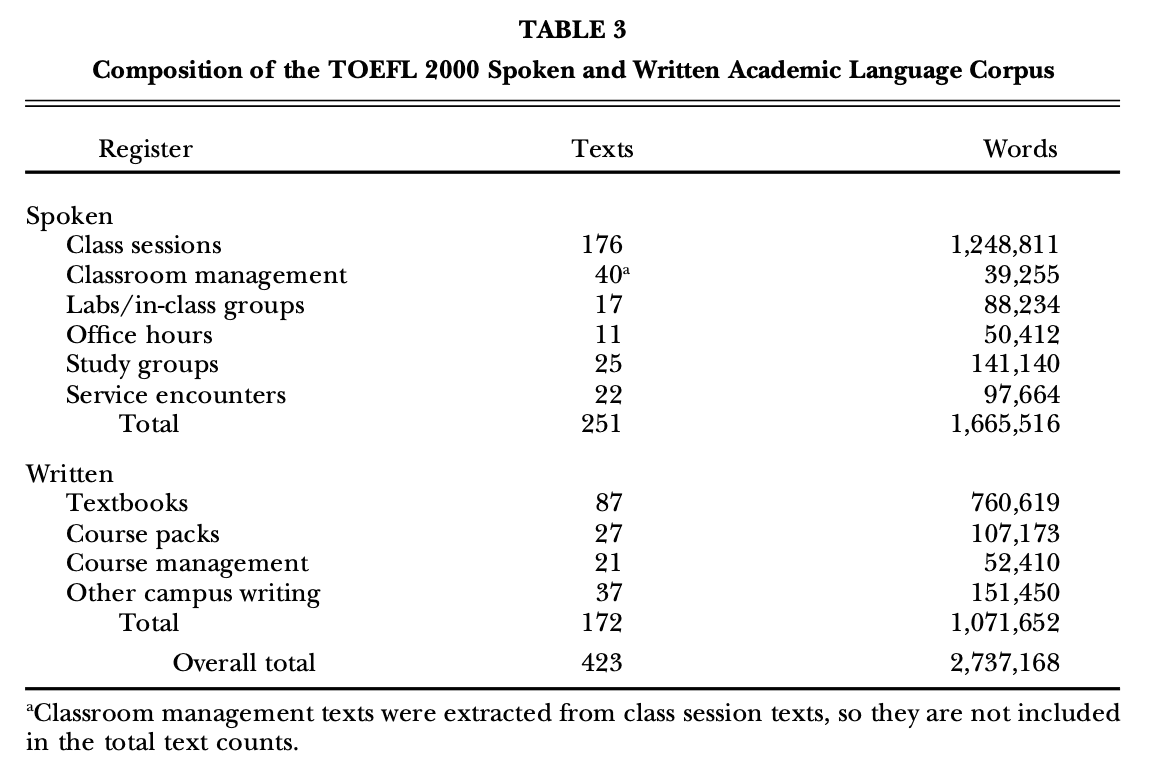
We designed the T2K-SWAL Corpus to be relatively large (2.7 million words) and to represent the academic registers that U.S. university students must listen to or read (see Table 3). The register categories chosen for the corpus reflect the spoken and written activities associated with academic life, including class sessions, office hours, study groups, on-campus service encounters, textbooks, course packs, and other campus writing (e.g., university catalogues, brochures). The sampling weight given to each register category reflects our assessment of its relative availability and importance.
To gather data, we identied and captured naturally occurring discourse at four academic sites (California State University, Sacramento; Georgia State University; Iowa State University; and Northern Arizona University). Taken together, the sites represent four U.S. regions—West Coast (California State), Rocky Mountain West (Northern Arizona), Midwest (Iowa State), and Deep South (Georgia State)—and four types of academic institutions—a teacher’s college (California State), a mid-size regional university (Northern Arizona), an urban research university (Georgia State), and a rural research university (Iowa State). Although we did not achieve full demographic/institutional representativeness, we aimed to avoid obvious skewing for these factors.
For the spoken corpus, our participants were primarily students, whom we recruited to record their academic conversations faculty. We also recruited faculty to record office hours and university staff to record service encounters. Student participants carried audiocassette recorders to capture academic speech as it occurred in the class sessions and study groups that they were involved in over a 2-week period, keeping a log of speech events and participants to the extent that it was practical. Faculty simply left cassette recorders running during their office hours (with student consent). This approach overcame the tendency for the somewhat artificial discourse that is often created by the presence of research assistants in spoken settings. We obtained high-quality, natural interactions; the main disadvantage was that we did not observe the interactions firsthand and thus could not obtain detailed information about the setting and participants.
Service encounters were recorded wherever students regularly interacted with staff to conduct the business of the university. These settings included the university bookstore, copy shop, and coffee shop; the front desk in the dormitory; academic department offices; the library information desk; the media center; and student business services.
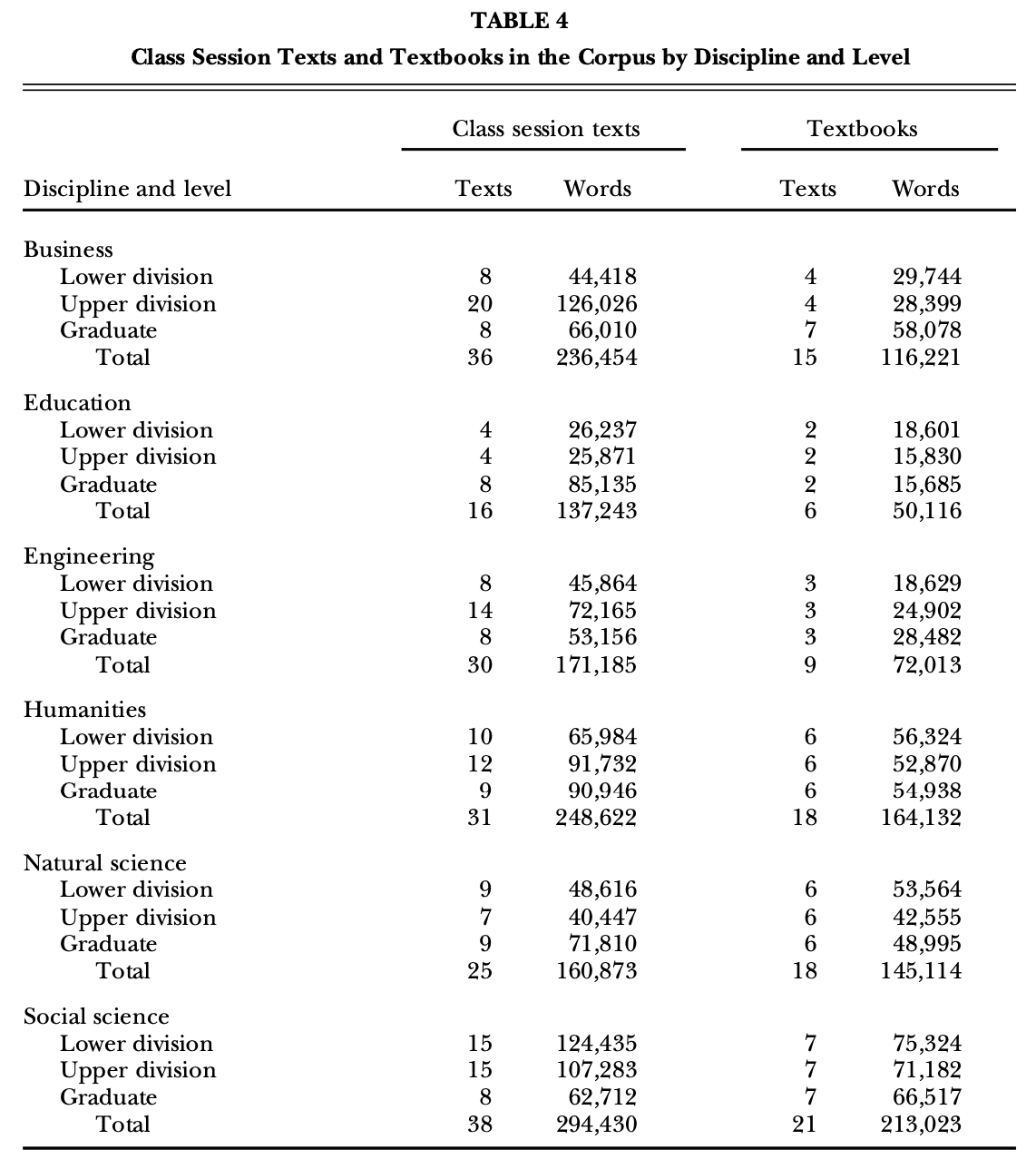
For class sessions and textbooks, we sampled spoken and written texts from six major disciplines (business, education, engineering, humanities, natural science, and social science) and three levels of education (lower-division undergraduate, upper-division undergraduate, and graduate). Table 4 shows the breakdown of texts by discipline and level for class sessions and for textbooks. Recognizing the existence of systematic variation within each of these high-level disciplines, we also targeted specific subdisciplines (e.g., chemistry, philosophy, psychology); although these distinctions will allow for register comparisons at a more specific level in future research, we restricted the study described here to the main categories. Finally, the corpus includes various teaching styles, as measured by the extent of interactivity in classroom teaching, but this study did not consider such distinctions.
Course packs collected for the corpus included written texts of several types: lecture notes, study guides, detailed descriptions of assignments or experimental procedures written by the instructor, and photocopies of published journal articles and book chapters. Course management texts are mostly syllabi, but this category also includes some written assignments or exams. Finally, the category other campus writing included the miscellaneous written texts that students encounter on campus, such as informational brochures about academic programs; university catalogues; Web pages describing academic programs; and informational brochures on student services, health or safety issues on campus, scholarships, and other topics. Although not often considered academic discourse, written material of this type is among the first that a prospective student receives from a university. It is ubiquitous on campus and is required reading for a prospective student attempting to navigate the maze of university requirements and services.
All texts in the corpus were coded with a header to identify content area and register. Spoken texts were transcribed using a consistent convention (see Edwards & Lampert, 1993), and to the extent possible speakers were distinguished and some demographic information for each (e.g., status as instructor or student) supplied in the header.
After editing all texts to ensure accuracy in transcribing and scanning, we grammatically annotated the texts using an automatic grammatical tagger (developed and revised over a 10-year period by Biber). The grammatical tags were then edited using an interactive grammar checker to ensure a high degree of accuracy for the final annotated corpus (see Biber et al., 1998, Methodology Boxes 4 and 5). For example, following is the tagged equivalent of the sentence The dissolved components that precipitate to form these rocks are decomposed from pre-existing rocks and minerals:
The ^ati++++
dissolved ^jj+atrb++xvbn+
components ^nns++++
that ^tht+rel+subj++
precipitate ^vb++++
to ^to++++
form ^vbi++++
these ^dt+dem+++
rocks ^nns++++
are ^vb+ber+aux++
decomposed ^vpsv++agls+xvbnx
from ^in++++
pre-existing ^jj+atrb++xvbg+
rocks ^nns++++
and ^cc++++
minerals ^nns++++
. ^.+clp+++
Question
How were the spoken texts transcribed in the corpus?
Answer the question above the continue reading. iTELL evaluation is based on AI and may not always be accurate.
For the quantitative linguistic comparisons of texts and registers, we used a computer program that calculated the rate of occurrence of linguistic features in each text (e.g., the number of nouns per 1,000 words). The linguistic variables analyzed in the T2K-SWAL Corpus for the purposes of the present study were the same features used for Biber’s (1988) factor analysis of general spoken and written registers (summarized above); 67 linguistic variables were analyzed (see Table 1 above). In the present study, we applied the dimensions from the 1988 factor analysis to compare university spoken and written registers. That is, we analyzed the same linguistic features in the texts of the T2K-SWAL Corpus and then calculated dimension scores for those texts.
To determine the distribution of university registers along each dimension, we compared texts and registers with respect to those dimension scores. The normalized linguistic feature counts are scores that show the rate of occurrence in texts (e.g., a noun score, an adjective score). In a similar way, dimension scores (or factor scores) can be computed for each text by summing the scores of the features having salient loadings on that dimension. In this study, only features with loadings greater than 0.35 on a factor were considered important enough to be used in computing dimension scores. For example, we computed the Dimension 1 score for each text by adding together the frequencies of private verbs, _that-_deletions, contractions, present tense verbs, and so on—the features with positive loadings on Factor 1 (from Table 1)—and then subtracting the frequencies of nouns, word length, prepositions, and so on—the features with negative loadings.
The individual linguistic variables were standardized to a mean of 0.0 and a standard deviation of 1.0 before the dimension scores were computed. This process translates the scores for all features to scales representing standard deviation units, so that all features on a factor have equivalent weights in the computation of dimension scores (see Biber, 1988, pp. 93–97).
Once a dimension score had been computed for each text, we computed the mean dimension score for each register. Plots of these mean dimension scores allow linguistic characterization of any given register, comparison of the relations between any two registers, and a fuller functional interpretation of the underlying dimension (see, e.g., Figure 1 below). In a similar way, standard statistical procedures (such as analysis of variance [ANOVA]) can be used to analyze the statistical significance of differences among the mean dimension scores.
To summarize the many features of the language in the corpus, we identify the texts’ positions along the five dimensions described in the Background section. This analysis shows how the university registers vary. We then explore this variation further by analyzing differences among texts associated with different disciplines and levels of study.
To describe the variation among registers, we plotted the mean dimension scores for the 10 university registers included in the T2K-SWAL Corpus based on the combined scores of the co-occurring features in each text (see Figures 1–5 below). Registers with large positive mean scores on a particular dimension contained high frequencies of the positive features for that dimension and low frequencies of its negative features (see Table 1 above). Conversely, registers with large negative mean scores on a dimension have high frequencies of the negative features of that dimension and low frequencies of the dimension’s positive features. These plots reveal several interesting findings about the linguistic characteristics of individual registers and about the patterns of variation among university registers. The statistics at the bottom of each figure report the results of an ANOVA to test for significant differences among the registers with respect to that dimension score. The _r^_2 value is a direct measure of strength, reporting the proportion of variance for the dimension score that can be predicted by the register distinctions. For example, Dimension 1 is a very strong predictor of register differences, with 88.9% of the variance for this dimension score predicted by register (see Figure 1). In the following subsections, we consider each dimension in turn.
University Registers Along Dimension 1: Involved Versus Informational Production
The distribution of university registers along Dimension 1 is surprising (see Figure 1). Previous multidimensional studies have interpreted Dimension 1 as a reflection of two underlying functional considerations: (inter)personal versus informational primary purpose and real-time versus careful production circumstances. Biber’s (1988) study of general spoken and written registers showed considerable overlap among registers along this dimension, reflecting the complex interplay of these factors. For example, prepared speeches (spoken) and fiction (written) both had Dimension 1 scores of around 0.0 (Biber, 1988, p. 128).

In contrast, spoken and written university registers were completely polarized along Dimension 1. All written registers had large negative scores, reflecting a frequent use of the negative features on Dimension 1 (e.g., nouns, long words, prepositions, attributive adjectives; see Table 1 above), coupled with the relative absence of positive features on this dimension. From a functional perspective, these negative scores indicate that the written registers are extremely informational in purpose and are produced under highly controlled and edited circumstances. Interestingly, the register of other campus writing has this same characterization even though the category is composed of nonacademic texts like brochures and university catalogues.
On the spoken end, all university registers had scores indicating high involvement, reflecting their frequent use of such features as present tense verbs, private verbs, first- and second-person pronouns, and contractions. The most surprising inclusion in this group was classroom teaching, which had a notably involved rather than informational characterization. This finding suggests that classroom teaching in U.S. universities is much more involved or interactive and less fully scripted than prepared speeches (including formal lectures) are. That is, whereas prepared speeches are carefully scripted and have a relatively informational characterization along Dimension 1, classroom teaching is more spontaneous and therefore is characterized by a greater use of features marking personal involvement and real-time production.
University Registers Along Dimension 2: Narrative Versus Nonnarrative Discourse
Relative to Dimension 1, the academic registers show little variation along Dimension 2 (see Figure 2). For the most part, university registers are characterized by the absence of narrative features. The written registers—especially other campus writing and course management— have especially large negative scores, representing an extremely low quantity of narrative features. Text Sample 2 above illustrates the absence of these features in a departmental Web page.

The absence of narrative features in textbooks is surprising, given the widespread perception that textbook authors from many disciplines rely heavily on narratives. However, this finding agrees with earlier MD studies of disciplinary writing (especially Conrad, 2001; see also Biber et al., 1998, pp. 158–163), which have shown that even textbooks for disciplines with a focus on the past do not typically rely on narrative discourse. That is, although these textbooks include some narratives written entirely in the past, present tense discussions of implications are much more common. The narrative sections may be perceptually salient, but they do not account for much of the total discourse in university-level textbooks. (Reppen, 2001, shows, however, that elementary school social science textbooks are much more narrative in general; see also Biber et al., 1998, pp. 180–188.)
In contrast to the norms for written registers, spoken university registers—especially study groups, office hours, and labs—show a greater tendency to use narrative features to some extent, resulting in Dimension 2 scores closer to 0.0. These scores reflect a mixing of purposes in these registers, including discussion and explanation of academic topics coupled with a recounting of past classroom teaching.
University Registers Along Dimension 3: Situation-Dependent Versus Elaborated Reference
Dimension 3, plotted in Figure 3, is similar to Dimension 1 in that it defines an absolute polar distinction between written and spoken university registers. Positive scores along this dimension represent a frequent use of time and place adverbials, reflecting situation-dependent reference, whereas large negative scores represent the frequent use of wh- relative clauses, phrasal coordination, and nominalizations, interpreted as elaborated reference.

Spoken university registers with large positive scores on Dimension 1 can be considered situation-dependent in some ways. These same registers commonly rely on directly situated reference, as reflected in their frequent use of adverbials that refer directly to the time and place of the speech event. Service encounters are especially marked for these features, but the academic interactive registers also use them frequently.
At the other extreme, written registers like textbooks and course packs are characterized by a dense use of relative clauses and phrasal coordination, reflecting styles of referring that are minimally dependent on the situational context. Interestingly, other campus writing is by far the most elaborated register along this dimension.
It is noteworthy that other campus writing is marked as the most “literate” register along Dimensions 1 and 3, reèecting an extremely dense concentration of complex nominal constructions, such as nouns, attributive adjectives, prepositional phrases, and technical vocabulary on Dimension 1, and wh- relative clause constructions on Dimension 3. This register is, in a sense, the front door to the university, as it includes the texts that all students must read to understand the procedures and requirements of university programs. It is therefore interesting that these texts should be more structurally complex than the content taught in university courses. This finding gives empirical linguistic support to the old saw about university catalogues: “If a student can read it, admit her or him. If she or he can understand it, give her or him a degree.”
University Registers Along Dimension 4: Overt Expression of Persuasion
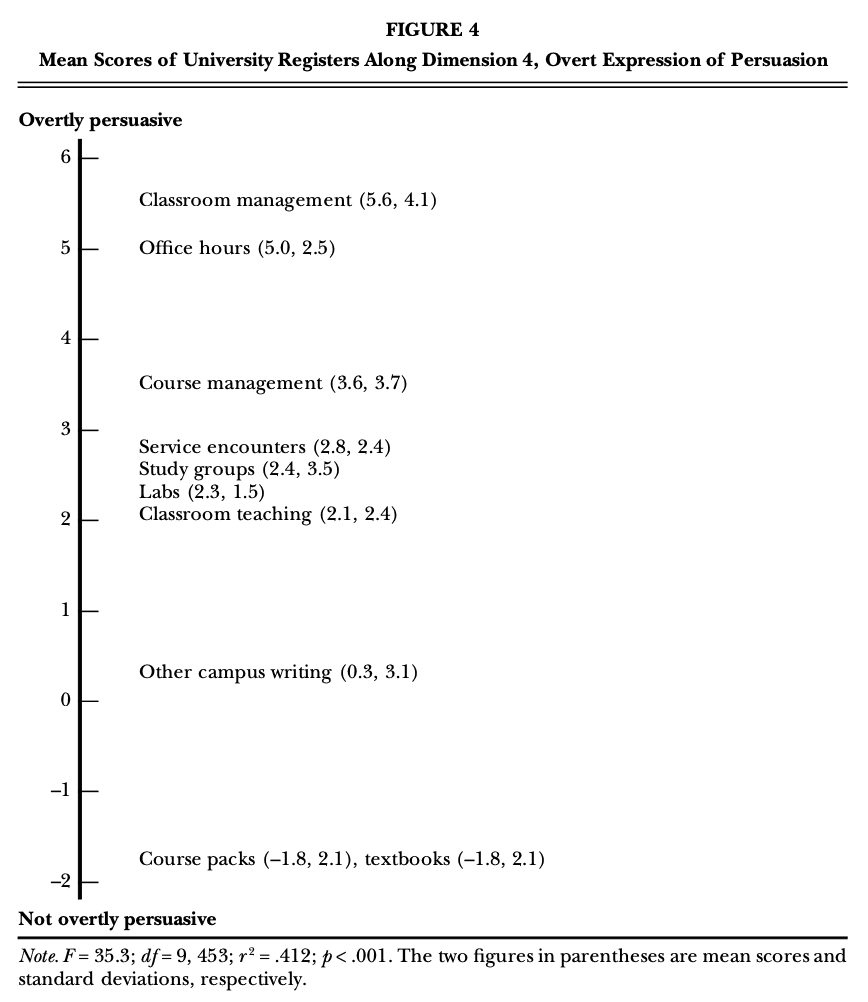
The defining features on Dimension 4 include several modal and semimodal verbs related to prediction (e.g., will, would, be going to) and necessity (e.g., must, should, have to). In addition, this dimension includes suasive verbs (e.g., command, demand, insist) and conditional subordination. These co-occurring features have been interpreted as reèecting an overtly persuasive style. Registers like newspaper editorials use these features to a greater extent than other registers do, but most previous MD studies found no register to be especially marked for these co-occurring features.
In contrast, all spoken university registers use these features relatively frequently (see Figure 4), and two of these registers—classroom management and office hours—are especially marked for their dense use. In addition, written course management shows a dense presence of these features. What these registers seem to have in common is their focus on behavior modification. Simply put, they try to persuade students to perform required tasks according to course specifications.
University Registers Along Dimension 5: Nonimpersonal Versus Impersonal Style
Along Dimension 5, texts vary in their use of passive constructions, including main-clause verb phrases and postnominal modiéers, and in their use of certain kinds of connecting words. Similar to the patterns observed along Dimensions 1 and 3, spoken and written registers show an absolute distinction along Dimension 5: All spoken registers in the corpus are marked by the absence of these passive constructions whereas all written registers use passive features frequently (see Figure 5).

The dense use of passives in textbooks serves as informational packaging. Noun phrases with the semantic role of agent or cause are less topically important than those with roles of patient or instrument; as a result, passive constructions are used to place the more important noun phrases in the grammatical subject position. The conjuncts explicitly mark the organization of the information and arguments. Surprisingly, these constructions are also common in other campus writing and in course management writing, which typically adopt an institutional rather than a personal voice. In these registers, references to students, the instructor, or the program administrator are often omitted, and the requirements, expectations, or other entities being inèuenced are fronted to the subject position, as illustrated by these excerpts from a department Web page:
the Master of Arts program in Anthropology is designed to . . .
when further information is required . . .
academic support is provided . . .
the groups are organized by the Center
and a course syllabus:
the order topics will be covered
students are expected to come to class prepared . . .
absences should be justiéed your homework should be done with pride and submitted on time
Question
What defines Dimension 3 along university registers?
Answer the question above the continue reading. iTELL evaluation is based on AI and may not always be accurate.
An analysis of dimension scores across disciplines and levels revealed some signiécant differences in textbooks but not in classroom teaching (see Appendixes A and B for descriptive statistics). ANOVAs (Table 5) showed signiécant differences for most dimensions among academic disciplines, within both classroom teaching and textbooks. However, these differences are generally not very strong, with r 2 values ranging from .06 to .36 (6–36%). Differences across levels are less marked, with all dimensions being nonsigniécant except Dimension 5 for textbooks.

These findings, coupled with those described in the previous section, show considerable linguistic variation across university registers on the éve dimensions and indicate that academic discipline and level are not associated with variation as much as register is. In fact, no signiécant variation was found among texts that differed in level, suggesting that students encounter generally the same structural linguistic features regardless of their level of study. As the preceding section has documented, texts in the various registers differ greatly in their linguistic features, but texts in the spoken and in the written modes show even greater differences. That is, regardless of speciéc purpose or subject matter, the physical mode of production seems to be by far the most important predictor of linguistic variation for university texts. Obviously, the analysis reported here did not capture all linguistic differences across university texts. In particular, we expect more detailed investigations of vocabulary and the extent of assumed technical background knowledge to reveal important differences across disciplines and levels. These differences might be even sharper if considered across speciéc academic disciplines (e.g., biology, philosophy, sociology) rather than across macrodisciplines (e.g., humanities, natural sciences) as they are here. Despite these caveats, the MD analysis reported here shows a surprising leveling of linguistic form used in classroom teaching and textbooks, with few structural differences across disciplines and levels.
In a few minor exceptions to this generalization, however, disciplines or levels differ in their dimension scores. Because the differences are much smaller than those discussed in the preceding sections and because the speciéc disciplines/levels are less well represented than the more general registers are, we offer only tentative interpretations of those differences here. First, business classroom teaching is somewhat more interactive than the norm along Dimension 1, involved versus informational production; natural science classroom teaching is somewhat less interactive (see Appendix A). Education textbooks are also somewhat more involved than the norm for textbooks. These differences may reèect disciplines’ preferred styles of instruction in teaching (i.e., class interaction vs. lecture style) and textbooks (i.e., a relatively interpersonal vs. a distanced relationship between the author and reader). Along Dimension 2, narrative versus nonnarrative discourse, the humanities and education registers are somewhat more narrative than other disciplines are; this is true of both classroom teaching and textbooks. In the humanities, this pattern reèects the importance of historical recounts in subdisciplines like history, religious studies, and philosophy. Education seems to show a similar focus on narrative (either personal or historical). The disciplinary differences along Dimension 3, situation-dependent versus elaborated reference, are more surprising, with classroom teaching in natural science and engineering (and, to a lesser extent, business) being considerably more situation dependent than the other disciplines. These patterns reèect the importance of physical demonstrations in the classroom teaching of those disciplines, with instructors repeatedly referring directly to displays or activities physically present in the classroom.
Surprisingly, engineering classroom teaching is also especially marked along Dimension 4, overt expression of persuasion, perhaps reèecting the same reliance on physical displays and demonstrations, and classes in which students are expected to consider alternative analyses and argue for a preferred solution.
Along Dimension 5, nonimpersonal versus impersonal style, engineering (and, to a lesser extent, natural science) is extremely marked for the dense use of passive constructions. This pattern éts the stereotypical characterization of technical and scientiéc prose. Interestingly, this difference exists only for textbooks; in contrast, we found no signiécant Dimension 5 differences among disciplines within lectures. As we noted above, classroom teaching and textbooks almost never differed in dimension scores across levels (see Appendix B and Table 5). The sole exception to this generalization is the Dimension 5 differences for textbooks: Passive constructions are somewhat less common in lowerdivision than in upper-division and graduate-level texts. Thus, for the features studied here, the only concession in linguistic style made to entering undergraduates—in either classroom teaching or textbooks—is a less dense use of passive constructions in textbooks. Regardless of level, classroom teaching is relatively interactive and noninformational (Dimension 1), situated and not referentially elaborated (Dimension 3), and not passive (Dimension 5). In contrast, textbooks are consistently informational (Dimension 1) and referentially elaborated (Dimension 3), again regardless of level.
The findings of our multidimensional analysis of speaking and writing at the university have important implications for teaching and future research. Perhaps most important is the perspective gained on the range of language that students encounter at universities. On all dimensions, the university registers were found to cover a wide spectrum. On all dimensions except Dimension 2, narrative versus nonnarrative discourse, the corpus contained registers falling at both ends. Students must deal not only with informationally dense prose but also with interactive and involved spoken registers. They must handle texts with elaborated reference as well as those that rely on situated reference, and texts with features of overt persuasion as well as texts that lack those features. They must understand discourse that uses an impersonal style with many passives as well as discourse that tends to avoid passives. One of the noteworthy contributions of this study, therefore, is to begin to describe the linguistic challenge faced by students in U.S. universities. Teachers and researchers need to be aware that part of this challenge is students’ need for facility in a tremendous range of registers. The distribution of registers along Dimension 1, involved versus informational production, is particularly important.
Academic registers are typically assumed to be extremely informational, but this study has shown that university students also encounter highly interactive, involved registers. Even registers with a strongly informational purpose, such as classroom teaching and study groups, are marked for the features of face-to-face interaction rather than the features of informational production. Previously, researchers and language teachers have paid little attention to the fact that students must rely on conversational language features to glean academic information from face-to-face interactions. Another important finding of this study is that most dimensions show a strong polarization between spoken and written registers. The written registers—regardless of their speciéc purpose—are characterized by informationally dense prose, a very nonnarrative focus, elaborated reference, few features of overt persuasion, and an impersonal style. (The exception to this pattern is the course management register, which frequently shows features of overt argumentation.) In contrast, the spoken registers—again regardless of purpose—are characterized by features of involvement and interaction, situated reference, more overt persuasion, and fewer features of impersonal style. This finding contrasts with those of previous MD studies of English, which did not énd spoken and written registers to be consistently polarized. For example, fiction writing is strikingly different from the written university registers considered here (see Biber, 1988, chapter 7). It falls near 0 on involved versus informational production (Dimension 1) and is marked strongly for the use of narrative features (Dimension 2), situation-dependent reference (Dimension 3), and nonimpersonal style (Dimension 5). Students may well read éction or other registers, such as newspapers, that have these relatively mixed proéles, but the oral and written university registers consistently differ in their features. This division in the academic registers is especially surprising given the numerous purposes represented in the T2K-SWAL Corpus. The spoken registers, for example, range from interpersonal interactions with both social and informational purposes (e.g., service encounters and study groups), to monologic discourse with a primary informational focus (e.g., some types of classroom teaching). Students are regularly expected to integrate spoken and written material (Carson et al., 1992); the éndings here suggest that this integration is likely to be challenging, given the polarization of linguistic characteristics across the modes.
This study has powerful implications for test development. The analysis describes the type of language that should inform such tests as the TOEFL if they are to accurately reèect the type of language used at universities. According to our results, students need the ability to handle not only academically dense prose but also interactive informational registers. In fact, Educational Testing Service is currently revising the TOEFL in part by using these data to check the consistency of test language with actual language use in university contexts (as represented in the T2K-SWAL corpus; see Educational Testing Service, 2001; Jamieson, Jones, Kirsch, Mosenthal, & Taylor, 2000). Materials for teaching EAP also need to reèect knowledge about registers used at the university. Like the TOEFL, practice materials need to integrate patterns of language forms that are typically used for particular functions at the university. (For further discussion of this issue, see Byrd & Reid, 1997; Conrad, 2000.) Students need practice with the wide range of registers that they will encounter when they undertake university work. This study has shown that even registers meant to welcome and help students—such as other campus writing, which includes handbooks, catalogues, and informational Web pages—present information in dense, complicated syntactic structures. These kinds of texts can make useful practice materials, though they are rarely thought of as academic texts. In addition to implications for testing and teaching, the results of this study also raise issues for university staff to consider. Most important is the énding that the register of other campus writing is extremely marked in its use of dense, informational prose. Most of the material in this category is meant to help students navigate policies and procedures or attract students to programs. Program administrators and advisers obviously want students to understand this information, but such dense prose seems unlikely to facilitate students’ understanding or attract them to programs. Less densely integrated prose would likely fit more closely the needs of the audience and the purpose of the texts.
Question
What is Educational Testing Service currently doing to revise the TOEFL?
Answer the question above the continue reading. iTELL evaluation is based on AI and may not always be accurate.
Although this study has revealed a great deal about the nature of language used at U.S. universities, more research is called for to expand the understanding of academic registers. For example, more detailed studies of speciéc disciplines might reveal similarities and differences across disciplines. Additional features—including rhetorical and lexical features—also deserve attention. In particular, vocabulary studies may uncover differences not identiéed in this MD analysis. The way students respond to the diverse registers at the university also merits attention (cf. Carkin, 2001). For example, how do students deal with the contrast between the interactive discourse of the classroom and the informational prose of the textbooks and course packets? Similarly, studies of instructors’ intentions would be valuable. Do instructors attempt to use interactional features of language to facilitate their instructional purpose in the classroom? Although many questions about academic language remain, this study has made a substantial contribution to the description of academic discourse, providing a relatively comprehensive analysis of language use in the university. Our hope is that this analysis will be especially useful in increasing the TESOL field's understanding of the language tasks that students face when they enter a U.S. university
This project was supported by Educational Testing Service. We thank the numerous research assistants and student workers from California State University, Sacramento; Georgia State University; Iowa State University; and Northern Arizona University who helped collect, transcribe, scan, tag, tag-edit, and analyze the corpus.
Douglas Biber is a Regents’ Professor in the Applied Linguistics Program at Northern Arizona University. His research interests have focused on register variation, grammar and discourse, and corpus linguistics. He has published books on these topics with Cambridge University Press (1988, 1995, 1998), Oxford University Press (1994), and Longman/Pearson (1999, 2001).
Susan Conrad is an associate professor in the Department of Applied Linguistics at Portland State University. Her interests include English grammar, writing in the academic disciplines, and the application of corpus linguistic techniques within TESOL. Her most recent book (edited with Douglas Biber) is Variation in English: Multi-Dimensional Studies (Pearson Education).
Randi Reppen teaches in Northern Arizona University’s MA-TESL and PhD in applied linguistics programs and directs the university’s Program in Intensive English. Her interests include corpus linguistics and materials development. She is a coauthor of Corpus Linguistics: Investigating Language Structure and Use (Cambridge University Press).
Patricia Byrd is a professor in the Department of Applied Linguistics and ESL at Georgia State University, where she teaches graduate courses in English grammar and materials design. Her publications include scholarly work on English grammar and Web-based instruction along with ESL textbooks focused on grammar and academic writing.
Marie Helt is an assistant professor of applied linguistics at California State University, Sacramento, where she coordinates the graduate TESOL program. Her research interests are in corpus linguistics and applied sociolinguistics, and she is involved in the American Egyptian Master Teacher Exchange Program through the U.S. Agency for International Development.
Last updated at